LA Bikeshare Data
After working on my Google Location History Notebook, I wanted to dig into spatial data a bit more. I’ve seen a number of different bikeshare data analyses in the past few years; I thought I would give it a try myself.
Extract: Get the data from LA Metro
Go to https://bikeshare.metro.net/about/data/ and download all the (1) trip data and (2) station information. As of 7/15/2017, there is one year of trip data released, separated by quarters. Everything is in CSV format.
##### Setup
%matplotlib inline
import urllib.request
import json
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point
import pysal as ps
import matplotlib.pyplot as plt
import datetime
import folium
import xlrd
import glob
import os
from datetime import timedelta
About LA Metro Bikeshare Data
Attribute information is provided directly on the LA Metro website. The station information contains the following fields:
- Station ID: Unique identifier for the station
- Station Name: Name of the station
- Go Live Date: Date that the station first became active
- Status: “Active” for stations available or “Inactive” for stations that are not available as of the latest update
The trip data contains the following fields:
- Trip ID (“trip_id”): Unique identifier for the trip
- Duration (“duration”): Duration of the trip, in minutes
- Start Time (“start_time”): Date/Time that the trip began, in ISO 8601 format in local time
- End Time (“end_time”): Date/Time that the trip ended, in ISO 8601 format in local time
- Start Station (“start_station”): Station ID where the trip originated
- Start Latitude (“start_lat”): Y coordinate of the station where the trip originated
- Start Longitude (“start_lon”): X coordinate of the station where the trip originated
- End Station (“end_station”): Station ID where the trip terminated
- End Latitude (“end_lat”): Y coordinate of the station where the trip terminated
- End Longitude (“end_lon”): X coordinate of the station where the trip terminated
- Bike ID (“bike_id”): Unique identifier for the bike
- Plan Duration (“plan_duration”): number of days that the plan the passholder is using entitles them to ride; 0 is used for a single ride plan (Walk-up)
- Trip Type (“trip_route_category”): One Way or Round Trip
- Passholder Type (“passholder_type”): Name of the passholders plan
Data Cleaning / Formatting
I’ll start by creating a few functions to help with the data cleaning and formatting process.
# Load data function to loop through all csvs in a folder and concatentate resulting dfs
def load_data(city):
path = 'data/' + city + '/trip_data'
csvs = glob.glob(os.path.join(path,'*.csv'))
dfs = (pd.read_csv(f) for f in csvs)
trips = pd.concat(dfs, ignore_index=True)
return trips
# Function to format trip start/end columns, subset first year of data
def time_format(trips_df):
trips_df['start_time'] = pd.to_datetime(trips_df['start_time'], errors='raise', infer_datetime_format='True')
trips_df['end_time'] = pd.to_datetime(trips_df['end_time'], errors='raise', infer_datetime_format='True')
trips_df = trips_df[(trips_df['start_time'] < min(trips_df['start_time']) + timedelta(days=365))]
return trips_df
# Load the trip data (4 quarters as of 7/17/2017).
la_trips = load_data('LosAngeles')
la_trips = time_format(la_trips)
Summary Statistics
Let’s start by looking at ridership by month and type of pass. In plotting a chart, I’m going to create a function to store the chart’s parameters so that I can quickly create one later again.
def generate_ridership_chart(trips):
# Aggregate by month / year along the count column
per_month = trips.start_time.dt.to_period("M")
g = trips.groupby([per_month, 'passholder_type'])
ridership_by_month = g.size()
# Create a bar chart showing the percentage of time spent doing each activity
ridership_chart = ridership_by_month.unstack().plot(kind='bar', stacked=True, title='Number of Trips each Month', figsize=(15,10), fontsize=12)
ridership_chart.set_xlabel("Year - Month", fontsize=12)
ridership_chart.set_ylabel("Trips", fontsize=12)
plt.show()
# Run the function for LA data
generate_ridership_chart(la_trips)
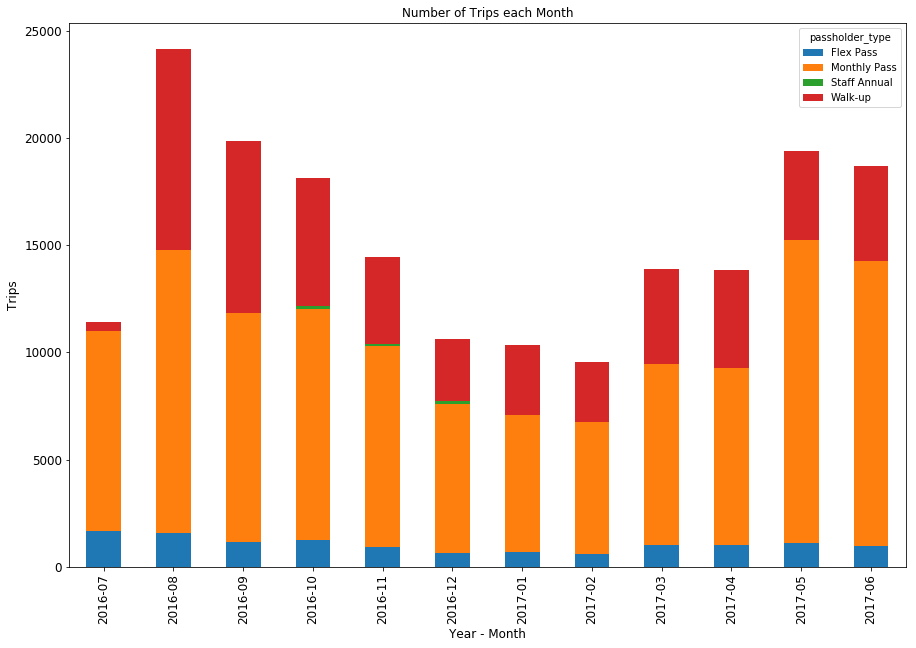
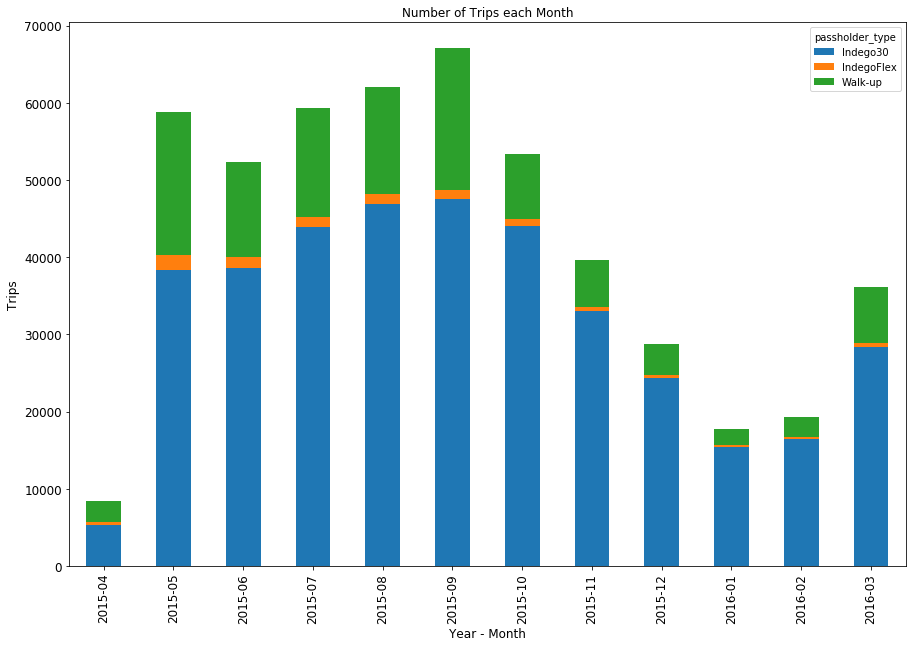
Systemwide Ridership by Month
There are about 15k - 20k trips per month for the bikeshare system. As expected, ridership dips down in the so-called winter months and ticks back up inthe spring and summer. However, it is interesting to see the magnitude of ridership dropoff during the winter months, given that the weather in southern california doesn’t vary all that much during those months.
The high mark for the program was the second month of operation, August 2016. Why not the first month? The system didn’t launch until July 7, 2016, which meant that July was missing a quarter month of ridership. More reasons for the August peak: Metro had an introductory 50 percent discount rate that was offered August - September 2016, so walk-up trips that were normally 3.50 were discounted to 1.75; looking at the stacked bar chart above, you can see that both August and September had Walk-Up ridership numbers that have not been attained since. Also, a number of people (including myself) got a free month of ridership; you can see the bump in monthly pass ridership in August that was not present in July or September.
This bar chart seems to show that the monthly pass ridership is surpassing the ridership in the first few months, while the number of walk-ups has declined, and the number of Flex Pass trips has remained more or less the same throughout the entire year. It is interesting that there are so few trips made using the Flex Pass, which is what I currently have. It is a $40 / yr pass that gets you a 1.75 trip 30-minute trip fare, instead of the 3.50 full fare for Walk-ups. Also interesting is the brief period where there were a small number of trips made through a Staff Annual Pass. This program seems to have only existed from October through December of 2016, and doesn’t look like it was that popular.
# Aggregate by day of the week
# dt.weekday assigns Monday=0, Sunday=6
per_dow = la_trips.start_time.dt.weekday
ridership_by_weekday = la_trips.groupby(per_dow).size().to_frame('trips')
weekday_labels = [['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday', 'Sunday']]
ridership_by_weekday = ridership_by_weekday.set_index(keys=weekday_labels)
# Bar chart with total weekday ridership
wkday_ridership_chart = ridership_by_weekday.plot(kind='bar',title='Total Number of Trips by Day of Week', legend=False, figsize=(15,10), fontsize=12)
wkday_ridership_chart.set_xlabel('Day of Week', fontsize=12)
wkday_ridership_chart.set_ylabel('Trips',fontsize=12)
plt.show()
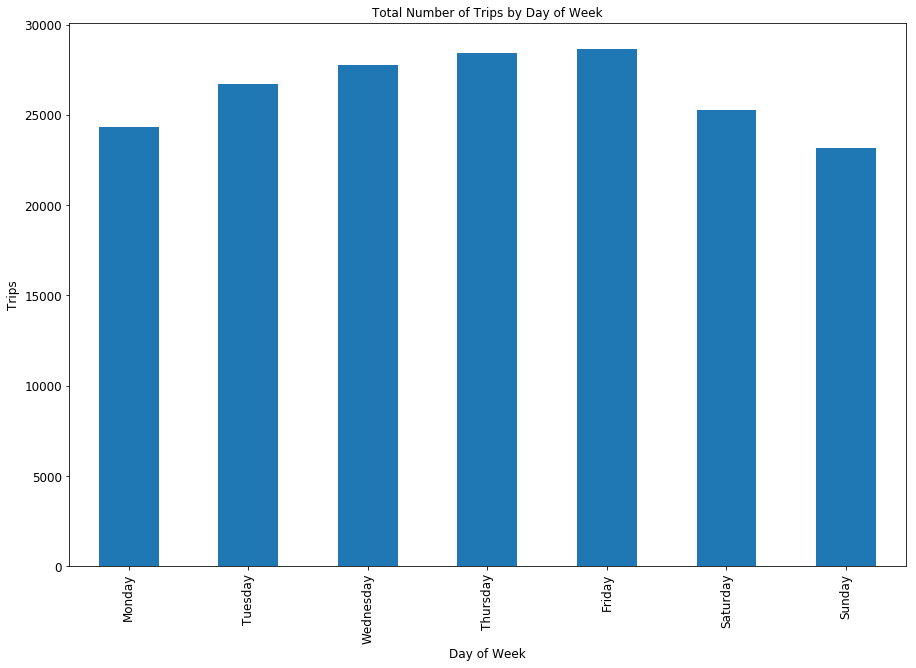
Bikeshare Ridership by Day of the Week
Looking at the ridership per day of the week, it is interesting, though not surprising, to see Friday as the day with the highest ridership. I believe Friday is the peak day for all trips; it likely also helps that Friday is often more dress casual compared to the rest of the week, so people may be more inclined to ride when they are in more comfortable clothing.
# Subset start_time from trips
trip_times = la_trips[['start_time']]
# Set the trip time as the index, replace the date values to a dummy date, and then delete the column
trip_times.index = trip_times['start_time']
trip_times.index = trip_times.index.map(lambda t: t.replace(year=2000, month=1, day=1))
del trip_times['start_time']
# Bucket the start times in 5 min increments & Plot the chart
trip_times_chart = trip_times.resample('5T').size().plot(legend=False)
trip_times_chart.set_xlabel("Start Time")
trip_times_chart.set_ylabel("Total Trips")
plt.show()
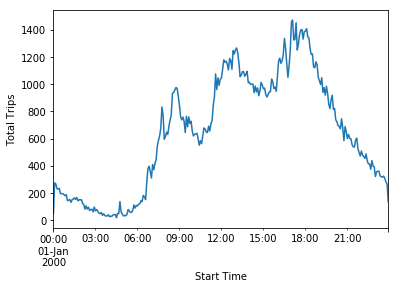
Bikeshare Ridership by Time of Day
This is interesting. In addition to the morning and evening peak commute times, there is also a lunch peak period of ridership. This also makes sense given that the stations are located only downtown, so there are fewer people who are able to use Metro Bikeshare to commute compared to those who are downtown for work during the day and want to use the system to get around downtown.
How Does Ridership Compare to Other Major Systems?
After 3 months of operation, the LA Times reported that LA’s system was not as well used compared to other bikeshare systems throughout the county. The LA Times picked 5 cities on this list (NY, Chicago, SF, DC, Santa Monica) and compared ridership to Metro’s system using the metric of trips per bike within the first three months of operation. This is a snapshot of what they found:
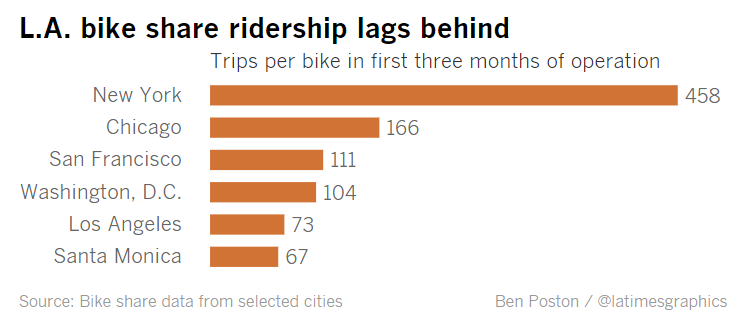
Now that we have a full year of data, I wanted to briefly look at comparing the LA system with bikeshare systems in other cities. I could start by looking at those 5 cities in the LA Times study, but I also wanted to expand the comparison to other bikeshare systems. Greater Greater Washington ranked all the bikeshare systems by size, measured by number of bikeshare stations. LA ranks 13th on this list, although I’m sure with the installation of stations in Pasadena (and soon enough in San Pedro as well) I’m sure this ranking will increase. Based on the Greater Greater Washington google spreadsheet, here is a table of the largest bikeshare systems in the U.S.
| Rank | City | Stations |
|---|---|---|
| 1 | New York | 645 |
| 2 | Chicago | 581 |
| 3 | Washington | 437 |
| 4 | Minneapolis | 197 |
| 5 | Boston | 184 |
| 6 | Miami | 147 |
| 7 | Topeka | 138 |
| 8 | Philadelphia | 105 |
| 9 | Portland | 100 |
| 10 | San Diego | 95 |
| 11 | Denver | 88 |
| 12 | Santa Monica | 86 |
| 13 | Los Angeles | 66 |
| 14 | Phoenix | 63 |
| 15 | Buffalo | 63 |
From this table, you can see that there were several systems larger than Metro’s but did not make the LA Times study, including Minneapolis, Boston, Miami, Topeka, Philadelphia, Portland, San Diego, and Denver. I want to include some of these in the analysis here.
Generate Charts for Other Bikeshare City Data
Here I load in and reformat the data from other bikeshare systems. Since most provide the files by calendar year, I load in two years of data and then filter out anything that is more than 1 year after the first ride in the system.
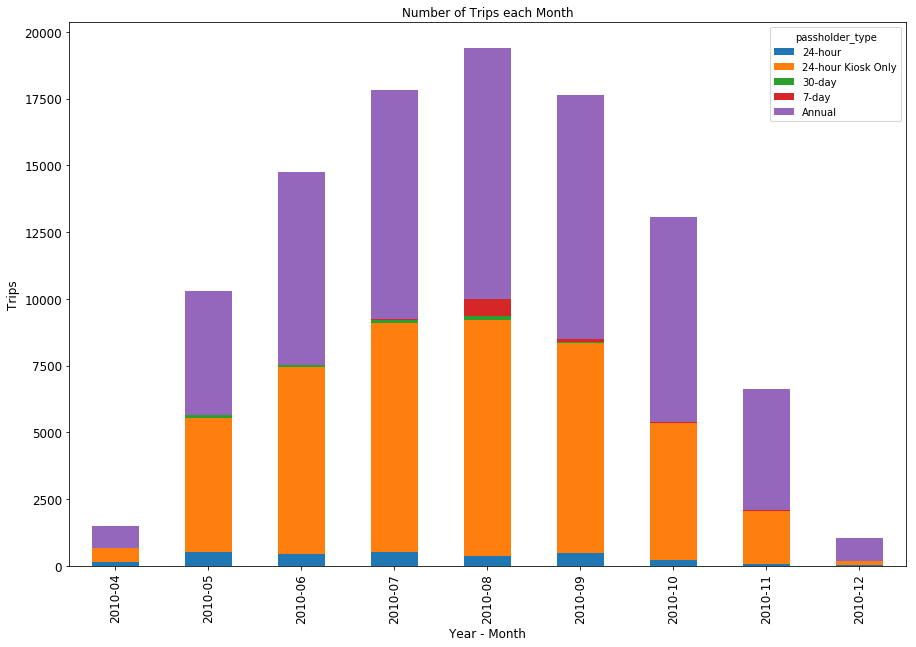
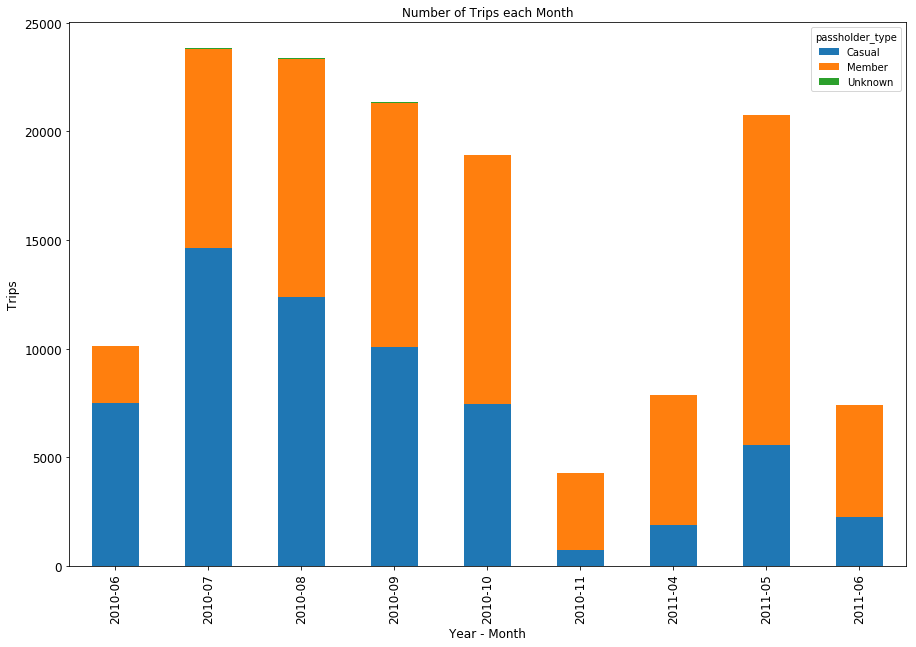
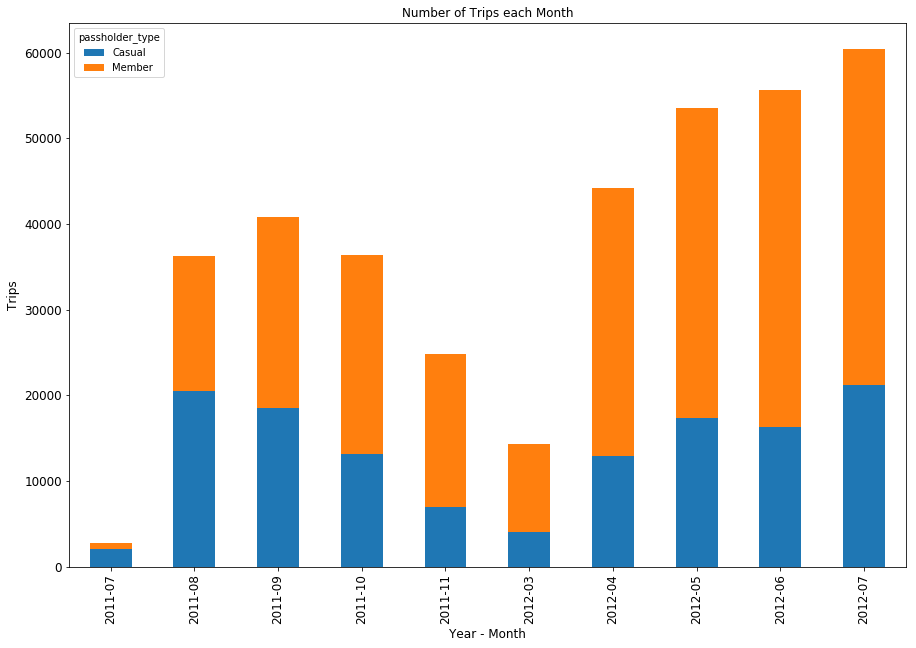
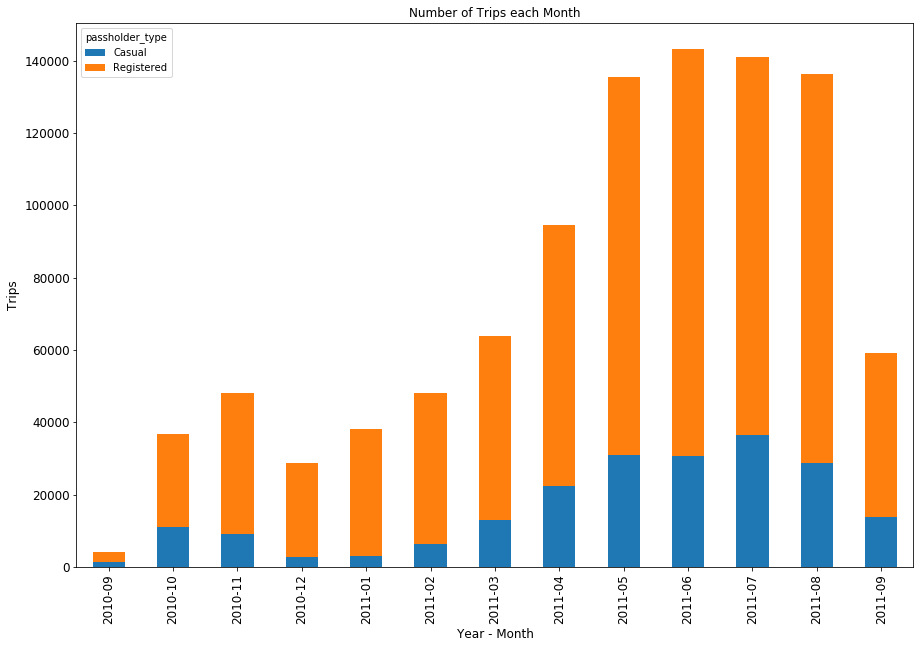
Some notes from looking at the initial one-year data of other systems-
- Just by looking at the way the data is formatted, you can immediately tell which systems share the same operator. Philadelphia and Los Angeles, for example, are operated by Bicycle Transit Systems, while
- A number of systems go dark in the winter.
- A few of the systems don’t include a bicycle_id field, which precludes me from doing the more detailed trips/bike/day calculation that I performed for LA.
# Load data function to loop through all csvs in a folder and concatentate resulting dfs
def load_data(city):
path = 'data/' + city + '/trip_data'
csvs = glob.glob(os.path.join(path,'*.csv'))
dfs = (pd.read_csv(f) for f in csvs)
trips = pd.concat(dfs, ignore_index=True)
return trips
# Function to format trip start/end columns, subset first year of data
def time_format(trips_df):
trips_df['start_time'] = pd.to_datetime(trips_df['start_time'], errors='raise', infer_datetime_format='True')
trips_df['end_time'] = pd.to_datetime(trips_df['end_time'], errors='raise', infer_datetime_format='True')
trips_df = trips_df[(trips_df['start_time'] < min(trips_df['start_time']) + timedelta(days=365))]
return trips_df
# Load / Format Denver Data
denver_path = 'data/Denver/trip_data/2010denverbcycletripdata_public.xlsx'
dv_trips = pd.read_excel(denver_path, parse_dates={'start_time':['Check Out Date', 'Check Out Time'],
'end_time':['Return Date','Return Time']})
dv_trips.rename(columns = {'Membership Type':'passholder_type',
'Bike':'bike_id',},
inplace=True)
# Load / Format Minneapolis Data
mn_trips = load_data('Minneapolis')
mn_trips.rename(columns = {'Start date': 'start_time',
'End date':'end_time',
'Account type':'passholder_type',
'Start terminal':'start_station_id',
'End terminal':'end_station_id'},
inplace=True)
mn_trips = time_format(mn_trips)
# Load / Format Boston Data
bs_trips = load_data('Boston')
bs_trips.rename(columns = {'Start date': 'start_time',
'End date':'end_time',
'Member type':'passholder_type',
'Bike number':'bike_id',
'Start station number':'start_station_id',
'End station number':'end_station_id'},
inplace=True)
bs_trips = time_format(bs_trips)
# Load / Format DC Data
dc_trips = load_data('WashingtonDC')
dc_trips.rename(columns = {'Start date': 'start_time',
'End date':'end_time',
'Member Type':'passholder_type',
'Bike#':'bike_id'},
inplace=True)
dc_trips = time_format(dc_trips)
# Load / Format Philadelphia Data
pa_trips = load_data('Philadelphia')
pa_trips = time_format(pa_trips)
print(min(mn_trips['start_time']))
2010-06-07 16:42:00
# Generate the ridership charts
generate_ridership_chart(dv_trips)
generate_ridership_chart(mn_trips)
generate_ridership_chart(bs_trips)
generate_ridership_chart(dc_trips)
generate_ridership_chart(pa_trips)
Station Information
Where is Metro Bikeshare?
I wanted to start by looking at the stations on a map. However, since the station information table doesn’t contain lat/lon coordinates, I would need to merge the tale with the trip data OR use the updated GeoJSON feed on the LA Metro website. I opted for the latter.
Bikeshare Ridership by Station
Let’s look at the differences in ridership by station, separating origins and destinations.
# Initially getting HTTP Forbidden Error, so added headers
url = "https://bikeshare.metro.net/stations/json/"
hdr = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding': 'none',
'Accept-Language': 'en-US,en;q=0.8',
'Connection': 'keep-alive'}
# Load the GeoJSON
req = urllib.request.Request(url, headers=hdr)
try:
response = urllib.request.urlopen(req)
except urllib.request.HTTPError as e:
print(e.fp.read())
station_json = json.loads(response.read())
# Import to GeoDataFrame
stations = gpd.GeoDataFrame.from_features(station_json['features'])
# Create basemap and add station points
station_map = folium.Map([34.047677, -118.3073917], tiles='CartoDB positron', zoom_start=11)
for index, row in stations.iterrows():
folium.Marker([row.geometry.centroid.y, row.geometry.centroid.x]).add_to(station_map)
station_map
# Load the station file
station_path = 'data/LosAngeles/station_data/metro_station_table.csv'
stations = pd.read_csv(station_path)
# First reformat stations df by setting station id as the index
stations = stations.set_index('Station ID')
# Count origins and destinations
stations_o_count = la_trips.groupby(la_trips['start_station_id']).size().to_frame('o_ct')
stations_d_count = la_trips.groupby(la_trips['end_station_id']).size().to_frame('d_ct')
# Combine O/D counts with station information
stations_od_count = pd.merge(stations_o_count, stations_d_count, right_index=True, left_index=True)
stations_count = pd.merge(stations, stations_od_count, left_index=True, right_index=True)
stations_count.head()
# Print out the max / min trip stats
print("The station with the highest number of origin trips is{}".format(stations_count.loc[stations_count['o_ct'].idxmax()][0]))
print("The station with the highest number of destination trips is{}".format(stations_count.loc[stations_count['d_ct'].idxmax()][0]))
The station with the highest number of origin trips is Broadway & 3rd
The station with the highest number of destination trips is Flower & 7th